前回の記事ではML-Agentのカリキュラム学習を、–initialize-from==RUN_IDオプションを使って行った。
https://kajindowsxp.com/ml-agents-initialize-learn/
今回はUnityのSceneをいくつも作成し、学習の進捗に応じてSceneを自動的に切り替えていくことで、カリキュラム学習を実装していく。
C#スクリプトと、Unity, ML-agentsの関係はこんな感じ。
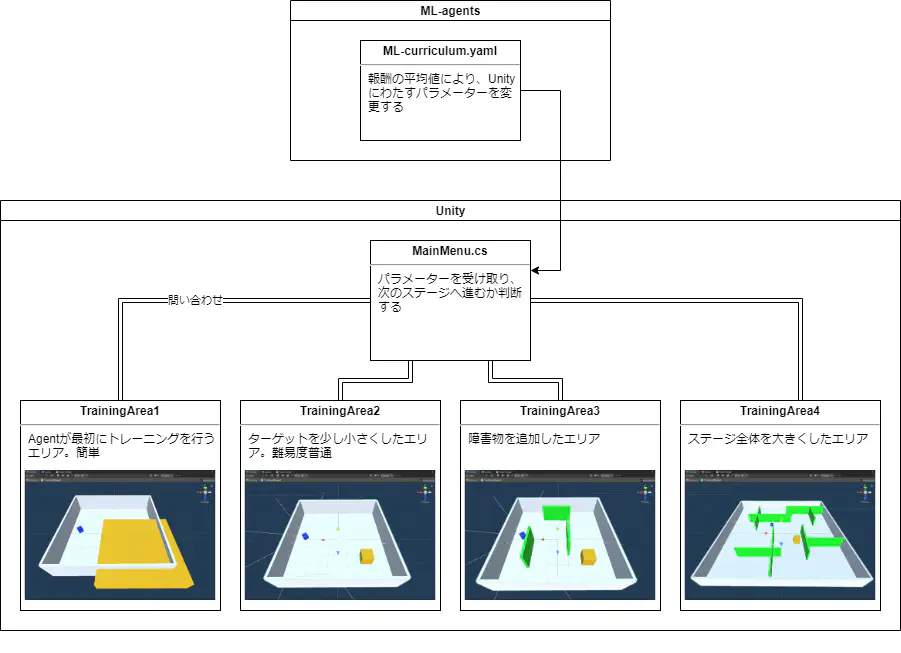
青いAgentが黄色いTargetを3秒間見つめ続けられたらクリア(=プラス報酬)となっている。詳しいルールとステージ解説は前回の記事を参照してほしい。
↓githubのソースコード
https://github.com/kajikentaro/ml-agents-curriculum
環境
- Windows10 64bit home
- python3-mlagents 0.23.0
- Unity 2019.4.17f1
- mlagents release12 1.7.2
yamlファイルの記述
yamlファイル進捗状況に応じたパラメーターを記載する。
ML-curriclumu.yaml
behaviors:
SearchTarget:
trainer_type: ppo
summary_freq: 10000
time_horizon: 64
max_steps: 10000000
keep_checkpoints: 5
checkpoint_interval: 500000
hyperparameters:
learning_rate: 3.0e-4
batch_size: 512
buffer_size: 10240
network_settings:
normalize: false
hidden_units: 128
num_layers: 3
environment_parameters:
stage_number:
curriculum:
- name: FirstTrain
completion_criteria:
measure: reward
behavior: SearchTarget
min_lesson_length: 100
threshold: 0.999
value: 1.0
- name: SecondTrain
completion_criteria:
measure: reward
behavior: SearchTarget
min_lesson_length: 100
threshold: 0.999
value: 2.0
- name: ThirdTrain
completion_criteria:
measure: reward
behavior: SearchTarget
min_lesson_length: 100
threshold: 0.98
value: 3.0
- name: ForthTrain
completion_criteria:
measure: reward
behavior: SearchTarget
min_lesson_length: 100
threshold: 0.95
value: 4.0C#スクリプトから、yamlの環境変数を取得する
この様なメソッドで取得できる。第一引数にenvironment_parametersの子要素で設定した文字列、第荷引数に存在しなかった場合のデフォルト値を設定する。
戻り地はfloat型
Academy.Instance.EnvironmentParameters.GetWithDefault("stage_number", -1.0f);MainMenu.csで組み立ててみるとこんな感じ。
floatをintにキャストして、その値に応じたsceneNameを辞書型クラスから参照できるようにした。
Dictionary<int, string> sceneName = new Dictionary<int, string> { { 1, "TrainingArea1" },{ 2, "TrainingArea2" },{ 3, "TrainingArea3" },{ 4, "TrainingArea4" } };
void newGame()
{
//yamlから学習の進捗に応じたステージ番号を取得
int newStageNumber = (int)Academy.Instance.EnvironmentParameters.GetWithDefault("stage_number", -1.0f);
//ステージ番号からステージをロードする。
SceneManager.LoadScene(sceneName[newStageNumber]);
}Scene推移が起こったときに、Agentを殺す
これをしないとSceneが放棄されているのにも関わらず内部のAgentへアクセスが続き、エラーが出まくる。
次のステージへ進む前に、今のステージで蠢いているAgentちゃんと、それにくっついているDecisionRequesterをDestroyしておくこと。
DestroyImmediate(GetComponent<DecisionRequester>());
DestroyImmediate(this.gameObject);その他
あとは今までと一緒の通り、実装を行えばいいわけだが、効率を上げるためAgentを複数同時に学習させるときには少しややこしい。
MainMenuをDontDestroyOnLoad(this)で放棄しないように設定し、Agentが死んだタイミングでカウンター(aliveAgent)をデクリメント、もしそれが0に達したらMainMenuから次のステージを呼び出すという方針にした。
なにかもっといいアイデアがあれば教えてほしい!
static int aliveAgent= 9;
static int nowStageNumber;
void Start()
{
//MainMenuを放棄しないよう(常に裏で動き続けるよう)にする。
DontDestroyOnLoad(this);
newGame();
}
void Update()
{
if (aliveAgent == 0)
{
aliveAgent = 9;
newGame();
}
}
//Agentから呼び出される関数
public static bool stageContinue()
{
int newStageNumber = (int)Academy.Instance.EnvironmentParameters.GetWithDefault("stage_number", -1.0f);
if (nowStageNumber == newStageNumber) return true;
return false;
}
//Agentから呼び出される関数
public static void agentDestroyed()
{
aliveAgent--;
}